When we talk about path computation in networks, we often frame it as a technical problem: algorithms, constraints, and optimization. But in practice, it’s just as much a human problem.
We don’t think in terms of individual links and nodes all day long. We think in regions, failure domains, performance expectations, and operational boundaries. We think in intent. The challenge is translating that intent into something a network can execute—without turning every path into a brittle, hand-crafted artifact.
Hybrid path computation sits at the intersection of human intent and automated decision-making, combining deterministic structure with adaptive flexibility. At its core, hybrid path computation allows operators to define where traffic should flow at a high level—while letting the network decide exactly how to realize that intent in real time.
The Limits of Fully Explicit Paths
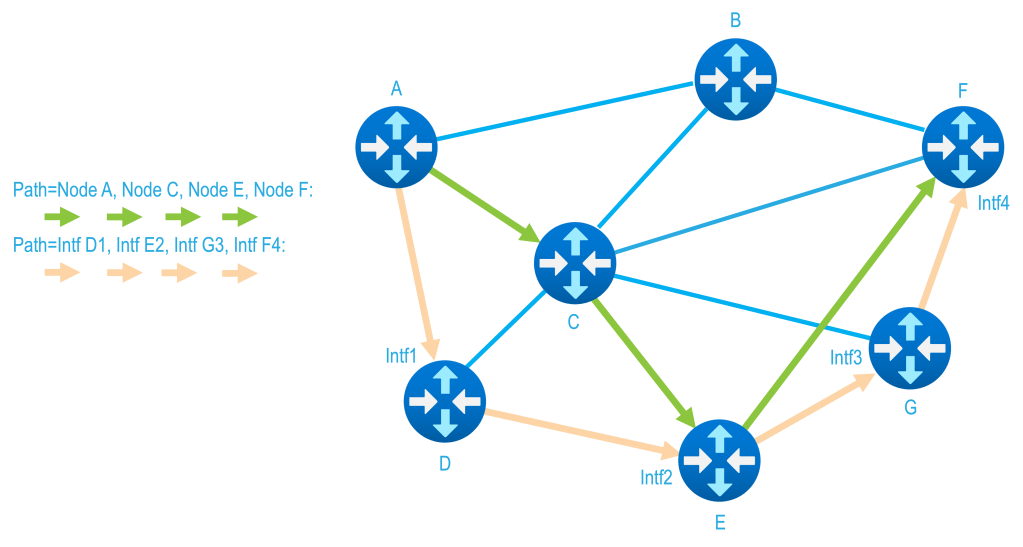
One traditional approach to traffic steering is to define an explicit sequence of nodes or waypoints that traffic must traverse. This method is precise and predictable: traffic goes through exactly the places you specify, in exactly the order you specify.
The downside is its fragile. If any single waypoint becomes unavailable—due to failure, congestion, or maintenance—the path either fails outright or relies on protection mechanisms that may not reflect the operator’s original intent.
Explicit paths provide control, but at the cost of adaptability — they demand additional engineering to accommodate a resource failure … such as a path protection scheme.
The Limits of Fully Abstract Constraints
At the other end of the spectrum, paths can be computed using abstract constraints instead of fixed waypoints. Rather than naming specific nodes, the operator defines characteristics the path must satisfy—such as performance attributes, risk separation, or administrative policies.
This approach is inherently more resilient. If one eligible resource becomes unavailable, the system can automatically choose another that meets the same criteria. You can influence the overall path, but not the sequence in which different types of regions or resources are traversed. Constraints can shape a path, but they don’t give you a way to say “first go through this kind of region, then through that one.” Everything blends together into a single optimization problem.
The downside is that structure disappears. For simple use cases, that’s fine. For real-world networks with geographic, policy, or operational boundaries, it quickly becomes limiting.
A More Natural Way to Think About Paths
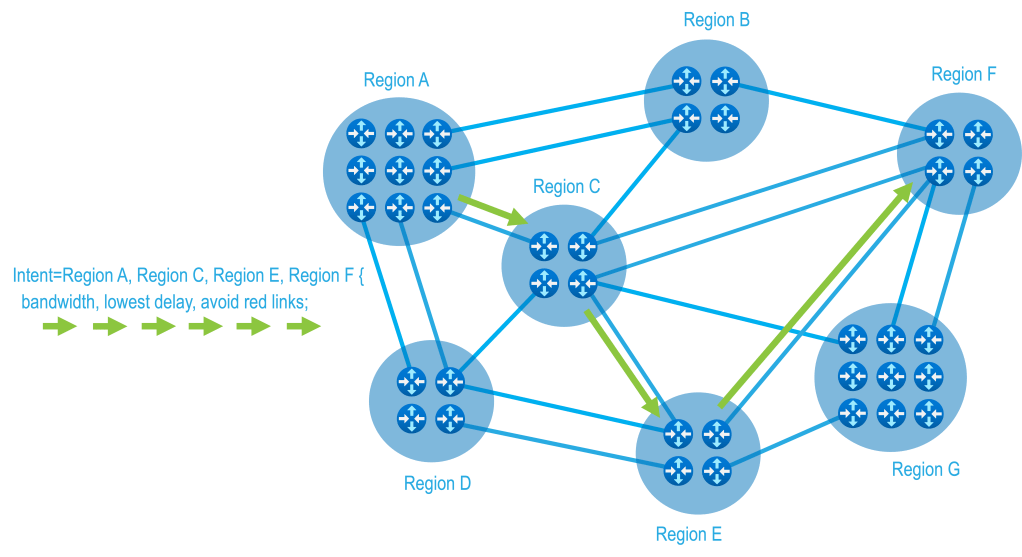
Hybrid path computation bridges the gap between being fully explicit and purely abstract by introducing ordered abstractions.
Instead of defining a path as either a strict list of individual waypoints, or a single, global set of constraints you define an ordered sequence of constraint groups. Each group represents a logical cluster of resources that meet a specific combination of requirements—performance, risk isolation, geography, policy, or any other relevant attributes. The path is computed by traversing these groups in sequence, while allowing the system to dynamically select the best available resource within each group.
In other words, the order is intentional and human defined. And the selection within each stage is automated and adaptive. This model preserves intent while embracing uncertainty.
Resilience Without Micromanagement
Because each hop in the path represents a group rather than a single resource, failure or congestion within that group does not invalidate the entire path. The system can seamlessly substitute an equivalent resource without violating the intended structure of the path.
Operators no longer need to choose between rigid paths that break easily and flexible paths that are hard to reason about. Hybrid path computation provides both predictability and resilience—without constant reconfiguration or the need for path protection schemes.
Sequencing Different Requirements Along a Path
Real networks often span multiple regions, each with different operational realities. One region of a path may prioritize low latency, another may prioritize risk separation, and another may prioritize capacity efficiency. Traditional models struggle to express this cleanly. Constraints typically apply globally, even when they only matter in certain parts of the network.
Hybrid path computation allows different constraint combinations to be applied in sequence. Each stage of the path can have its own requirements, mapped to its own group of eligible resources. This makes it possible to express nuanced, real-world intent without inventing new labels, tags, or classifications across the entire network.
Centralized Intent, Distributed Execution
This model works because it respects how networks are actually operated. Engineers can define intent in one place, in terms that make sense to them: order, policy, and desired behavior. From there, the network does the heavy lifting.
Another key benefit of this approach is operational simplicity. The intelligence lives at the point where intent is defined—typically at an ingress or control layer—while the rest of the network continues to operate unchanged.
Intermediate devices don’t need to be reconfigured or taught new concepts. They simply participate using attributes that already exist. The intelligence is in how those attributes are combined, not in how many new ones are created.
Why This Matters
We [engineers] tend to think in terms of regions, policies, and failure domains—not individual links. At the same time, we expect the network to adapt dynamically to real-time conditions.
By combining ordered structure with abstract flexibility, hybrid path computation enables networks that are:
- easier to reason about,
- more resilient to change,
- and better aligned with human intent.
It’s not about choosing between centralized or distributed intelligence, or between explicit paths and constraint-based routing. It’s about combining the strengths of each—so the network can do what it does best, while operators stay firmly in control of the outcome.
Disclaimer
The opinions, analyses, and recommendations expressed in any post, comment, or other content on tedigest.com are solely those of the individual authors. They do not represent the official policies, positions, or endorsements of the authors’ current or former employers and affiliated organizations.

Leave a comment